
Onderstaande tekst is geanonimiseerd. De exacte namen van mensen en bedrijven zijn niet relevant. De blog is geschreven om lessons learned te delen.
In deel 1 van deze blogserie hebben we uitgelegd wat er gebeurde n.a.v. de “cry for help” van Jan, en Jan’s bedrijf. Voor wie dat gemist heeft, zie https://m2-d2.com/nl/can-you-take-over-part-1/. In dit tweede deel pakken we draad weer op. Het platform is live gegaan en er is een lijst van meer dan tachtig change requests, maar zonder prioriteiten. En toen …
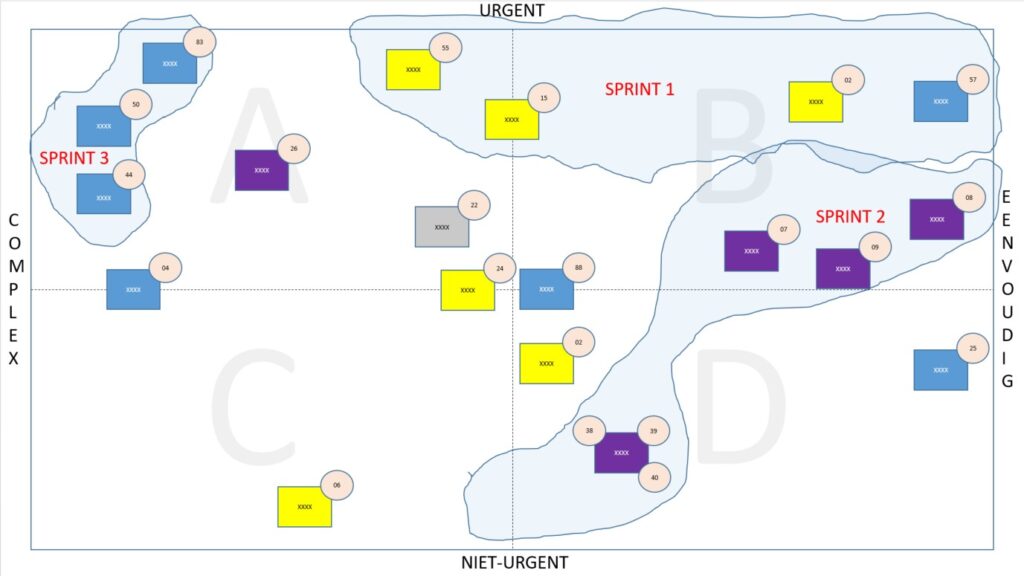
Samen met Jan en zijn functioneel beheerder deden we een workshop waarin we alle change requests scoorden in een matrix. Op de ene as “urgent vs. niet urgent” en op de andere as “complex vs. eenvoudig”. Vervolgens kregen de diverse tickets ook nog een kleurtje afhankelijk van de component van het totale platform waarop een ticket betrekking had. Onderstaand een geanonimiseerd voorbeeld van een van de vele platen die dat opleverde waarbij groepen van tickets, “waves”, bij elkaar genomen zijn om in samenhang te gaan oppakken, in "sprints".
Naast de functionele tickets hebben we ook tijd ingebouwd om de logging en monitoring te verbeteren. Debuggen zonder logging is namelijk best lastig. En IT platformen hebben nou eenmaal de neiging, zeker als er gebruikt gemaakt wordt van API calls naar een externe mailserver e.d., om wel eens te blijven hangen. Dan is tijdige alerting zeker geen overbodige luxe.
Vanaf januari zijn we gaan werken met sprints van drie weken. Ook hebben we zo snel mogelijk naast de productieomgeving (PROD) en de developmentomgeving (DEV) een user acceptance test omgeving (UAT) geïmplementeerd. Jan’s bedrijf was gewend om changes direct op de PROD te krijgen en dan te testen op die PROD maar da’s natuurlijk niet wat je wilt. Als er dan iets fout gaat hebben je gebruikers, intern en extern, er last van. En wat ook belangrijk is … welke gebruikersorganisatie lukt het om vooraf volledig te beschrijven wat de gewenste functionele wijziging behelst? Exact, geen een!!!! Zo’n gebruikersorganisatie bestaat niet. Zeker niet op MKB niveau. Da’s niet erg, maar dan is een UAT omgeving nog eens van extra nut om voor het live gaan de exacte requirements scherp te krijgen. Het definiëren van requirements is vaak een vak apart. Een proces beschrijven zoals het exact, in het meest positieve geval, zou moeten verlopen, lukt nog wel. Maar ieder proces kent een heleboel potentiele “afslagen”. Inputs die niet verstrekt worden zoals gewenst, een gebruiker die in een andere volgorde op buttons clickt dan je zou willen, etc. En ja, je moet ook vooraf bedenken hoe je met al die uitzonderingen wilt omgaan. Qua gebruikersinteractie, qua procesflow, qua dataopslag.
Het woord viel al eerder: “sprints”. Ontwikkeltrajecten van in ons geval drie weken waarin een verzameling tickets wordt opgepakt die aan het einde van die sprint worden opgeleverd in UAT om te laten testen door de gebruikersorganisatie zodat ze, na goedkeuring, naar PROD gedeployed kunnen worden. Oftewel: live gaan. Lekker agile werken. Het lijkt voor ons IT-ers zo logisch allemaal. Maar nou naar de gebruiker, de klant. Die kent Wordpress voor zijn website. Die denkt dat het toevoegen van een nieuwe pagina met nieuwe vragen een kwestie van 30 minuten werk is. Die beseft niet dat het platform niet in Wordpress gebouwd is maar in Python/Django met vue.js. Die beseft niet dat de data die aan de voorkant als input wordt vekregen ook aan de achterkant in de database moet worden opgeslagen. En vervolgens via allerlei schermen weer teruggekeken dient te worden. (Want wat heb je er anders aan om het aan de voorkant uit te vragen …?) Die beseft niet dat die nieuwe inputs aan de voorkant via aan te paasen APIs naar derde partijen gecommuniceerd moet worden. En die ook niet beseft dat als alles getest en goedgekeurd is op UAT (“waarom niet gelijk op productie?” blijft nog wel een tijdje terugkomen, ook al heb je uitgelegd dat dat niet slim is), het deployen van alleen die change een halve dag is, terwijl het werken in sprints betekent dat je na 3 weken ALLE wijzigingen in 1 keer deployed zodat het niet 10 x maar slechts 1 x een halve dag kost!
Ook hier weer: rustig blijven, en keer op keer uitleggen in zoveel mogelijk gewone, dus niet IT-mambo-jambo, taal hoe het werkt en waarom we het zo doen. En bovenal: accepteren dat er altijd een spanningsveld is en blijft tussen de gebruiker die het “morgen” wil hebben en degene die verantwoordelijk is voor het efficiënt opleveren van effectief en veilig werkende programmatuur. That’s life.
Diezelfde aanpak van rustig blijven en keer op keer uitleggen is van toepassing op wat voor ons IT-ers zo logisch lijkt: operationeel beheer. Dat er operationeel beheer nodig is voor een maatwerkplatform is iets dat soms lastig te begrijpen valt door een klant. De metafoor “als ik een auto koop hoef ik ook maar één keer per jaar naar de garage voor een onderhoudsbeurt” kan ik inmiddels wel dromen. En soms helpt uitleggen niet, maar moet je iets laten gebeuren. De mail server die op een gegeven moment een keer vastloopt is dan zo’n voorval. Dan los je dat razendsnel op en zeg je “da’s nou ook beheer”. Maar het blijft een lastige discussie, ook omdat behoud van kennis van het platform essentieel is om dat operationele beheer te kunnen doen en er dus kosten gemoeid zijn met het beschikbaar houden van die kennis. Wil je daar niet voor betalen, dan gaan de mensen metr die kennis aan andere projecten werken en zijn ze niet zo maar vrij te maken als Jan of een van zijn mensen aangeeft dat het platform niet doet wat het zou moeten doen. “Dan stel je toch een SLA op”, hoor ik mensen zeggen. Ja, graag, maar dat betekent dat Jan maandelijks kosten voor operationeel beheer heeft en dat ... doet pijn. De enige optie: uitleggen, uitleggen, adem halen en nog eens uitleggen :-)
Deel 3 van deze blogserie is het laatste deel. Daarin geven we antwoord op twee vragen. Zouden we het morgen weer doen? En zo ja, zouden we het dan anders aanpakken?
