
The text below has been anonymised. The exact names of people and companies are irrelevant. The blog is written to share lessons learned.
In part 1 of this blog series, we explained what happened after Jan’s “cry for help”, and Jan’s company. For those who missed that, see https://m2-d2.com/en/can-you-take-over-part-1/. In this second part we pick up thread again. The platform has gone live and there is a list of more than eighty change requests, but without priorities. And then …
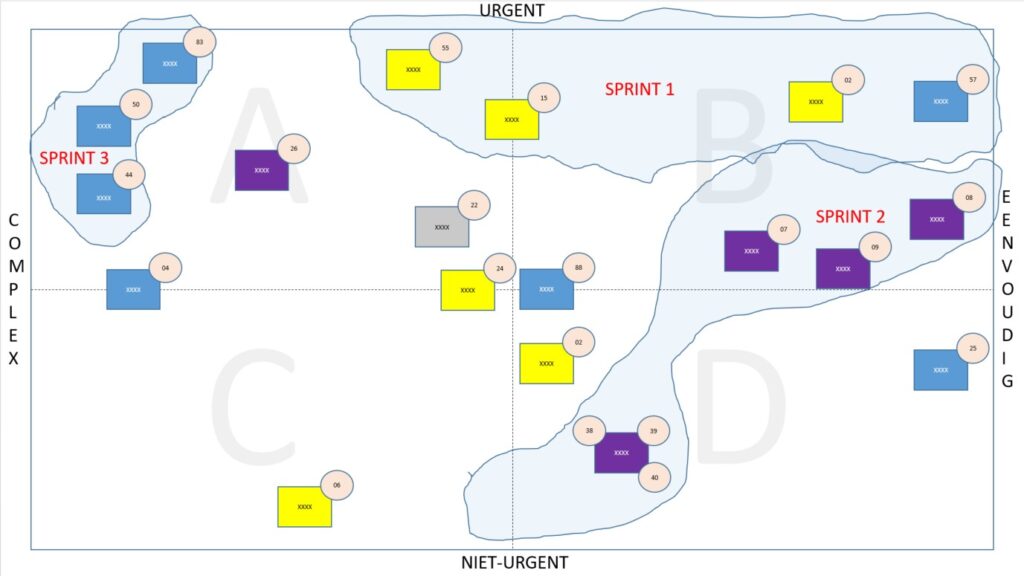
Together with Jan and his functional administrator, we did a workshop in which we scored all change requests in a matrix. On one axis “urgent vs. not urgent” and on the other axis “complex vs. simple”. Subsequently, the various tickets were also given a color depending on the component of the total platform to which a ticket related. Below is an anonymized example of one of the many records that resulted in which groups of tickets, “waves”, are taken together to start working together, in “sprints”.
In addition to the functional tickets, we have also built in time to improve logging and monitoring. Debugging without logging is quite difficult. And IT platforms simply have the tendency, especially when using API calls to an external mail server, etc., to get stuck sometimes. Then timely alerting is certainly not an unnecessary luxury.
From January we started working with sprints of three weeks. We also implemented a user acceptance test environment (UAT) in addition to the production environment (PROD) and the development environment (DEV) as quickly as possible. Jan’s company was used to getting changes directly on the PROD and then testing on that PROD, but of course that’s not what you want. If something goes wrong, your users, internally and externally, will suffer. And what is also important … which user organization manages to fully describe in advance what the desired functional change entails? Exactly, none!!!! Such a user organization does not exist. Certainly not at the SME level. That’s not a bad thing, but then a UAT environment is even more useful to get the exact requirements clear before going live. Defining requirements is often a profession in itself. Describing a process as exactly, in the most positive case, should proceed, is still possible. But every process has a lot of potential “turns”. Inputs that are not provided as desired, a user who clicks on buttons in a different order than you would like, etc. And yes, you also have to think in advance how you want to deal with all those exceptions. In terms of user interaction, in terms of process flow, in terms of data storage.
The word came up earlier: “sprints”. In our case, development processes of three weeks in which a collection of tickets is picked up and delivered to UAT at the end of that sprint for testing by the user organization so that, after approval, they can be deployed to PROD. In other words: go live. Nice agile working. It all seems so logical to us IT people. But now to the user, the customer. He knows WordPress for his website. Who thinks that adding a new page with new questions is a matter of 30 minutes of work. He does not realize that the platform is not built in WordPress but in Python/Django with vue.js. He does not realize that the data that is received as input at the front must also be stored in the database at the back. And then you have to look back through all kinds of screens. (Because otherwise what good is it to ask it out at the front…?) They don’t realize that those new inputs at the front have to be communicated to third parties via APIs that can be adapted. And who also does not realize that if everything has been tested and approved on UAT (“why not the same on production?” will come back for a while, even if you explained that it is not smart), deploying only that change is half day, while working in sprints means that after 3 weeks you deploy ALL changes in 1 time so that it does not cost 10 x but only 1 x half a day!
Again: stay calm, and explain time and time again in as much normal, so not IT-mambo-jambo, language as possible how it works and why we do it that way. And above all: accepting that there is and will always be a field of tension between the user who wants it “tomorrow” and the person who is responsible for the efficient delivery of effective and safe working software. That’s life.
That same approach of staying calm and explaining over and over applies to what seems so logical to us IT people: operations management. The fact that operational management is required for a custom platform is something that is sometimes difficult for a customer to understand. I can now dream of the metaphor “when I buy a car, I only have to go to the garage once a year for maintenance”. And sometimes explaining doesn’t help, you have to let something happen. The mail server that crashes at some point is such an incident. Then you solve that very quickly and say “that’s also management”. But it remains a difficult discussion, also because retaining knowledge of the platform is essential to be able to do that operational management and therefore costs are involved in keeping that knowledge available. If you don’t want to pay for that, the people with that knowledge will work on other projects and they won’t be released just like that if Jan or one of his people indicates that the platform is not doing what it should. “Then you draw up an SLA after all”, I hear people say. Yes, please, but that means that Jan has monthly costs for operational management and that … hurts. The only option: explain, explain, breathe and explain again 🙂
Part 3 of this blog series is the last part. In it we answer two questions. Would we do it again tomorrow? And if so, would we approach it differently?
